
|
|
1 год назад | |
|---|---|---|
| .. | ||
| include | 1 год назад | |
| AUTHORS | 1 год назад | |
| CMakeLists.darwin-x86_64.txt | 1 год назад | |
| CMakeLists.linux-aarch64.txt | 1 год назад | |
| CMakeLists.linux-x86_64.txt | 1 год назад | |
| CMakeLists.txt | 1 год назад | |
| CMakeLists.windows-x86_64.txt | 1 год назад | |
| LICENSE_1_0.txt | 1 год назад | |
| README.md | 1 год назад | |
| ya.make | 1 год назад | |
README.md

![]()
miniselect: Generic selection and partial ordering algorithms
miniselect is a C++ header-only library that contains various generic selection
and partial sorting algorithms with the ease of use, testing, advice on usage and
benchmarking.
Sorting is everywhere and there are many outstanding sorting algorithms that compete in speed, comparison count and cache friendliness. However, selection algorithms are always a bit outside of the competition scope, they are pretty important, for example, in databases ORDER BY LIMIT N is used extremely often which can benefit from more optimal selection and partial sorting algorithms. This library tries to solve this problem with Modern C++.
- Easy: First-class, easy to use dependency and carefully documented APIs and algorithm properties.
- Fast: We do care about speed of the algorithms and provide reasonable implementations.
- Standard compliant: We provide C++11 compatible APIs that are compliant to the standard
std::nth_elementandstd::partial_sortfunctions including custom comparators and order guarantees. Just replace the names of the functions in your project and it should work! - Well tested: We test all algorithms with a unified framework, under sanitizers and fuzzing.
- Benchmarked: We gather benchmarks for all implementations to better understand good and bad spots.
Table of Contents
- Quick Start
- Testing
- Documentation
- Performance results
- Real-world usage
- Contributing
- Motivation
- License
Quick Start
You can either include this project as a cmake dependency and then use the headers that are provided in the include folder or just pass the include folder to your compiler.
#include <iostream>
#include <vector>
#include "miniselect/median_of_ninthers.h"
int main() {
std::vector<int> v = {1, 8, 4, 3, 2, 9, 0, 7, 6, 5};
miniselect::median_of_ninthers_select(v.begin(), v.begin() + 5, v.end());
for (const int i : v) {
std::cout << i << ' ';
}
return 0;
}
// Compile it `clang++/g++ -I$DIRECTORY/miniselect/include/ example.cpp -std=c++11 -O3 -o example
// Possible output: 0 1 4 3 2 5 8 7 6 9
// ^ on the right place
Examples can be found in examples.
We support all compilers starting from GCC 7 and Clang 6. We are also planning to support Windows, for now it is best effort but no issues are known so far.
More on which algorithms are available, see documentation. For overview of this work you can read the article in the author's blog.
Testing
To test and benchmark, we use Google benchmark library. Simply do in the root directory:
# Check out the libraries.
$ git clone https://github.com/google/benchmark.git
$ git clone https://github.com/google/googletest.git
$ mkdir build && cd build
$ cmake -DMINISELECT_TESTING=on -DBENCHMARK_ENABLE_GTEST_TESTS=off -DBENCHMARK_ENABLE_TESTING=off ..
$ make -j
$ ctest -j4 --output-on-failure
It will create two tests and two benchmarks test_sort, test_select,
benchmark_sort, benchmark_select. Use them to validate or contribute. You
can also use ctest.
Documentation
There are several selection algorithms available, further is the number
of elements in the array,
is the selection element that is needed to be found (all algorithms are deterministic and not stable unless otherwise is specified):
| Name | Average | Best Case | Worst Case | Comparisons | Memory |
|---|---|---|---|---|---|
| pdqselect | At least |
||||
| Floyd-Rivest | Avg: |
||||
| Median Of Medians | Between |
||||
| Median Of Ninthers | Between |
||||
| Median Of 3 Random | At least |
||||
| HeapSelect | |||||
| libstdc++ (introselect) | At least |
||||
| libc++ (median of 3) | At least |
For sorting the situation is similar except every line adds comparisons and pdqselect is using
memory.
API
All functions end either in select, either in partial_sort and
their behavior is exactly the same as for
std::nth_element
and std::partial_sort
respectively, i.e. they accept 3 arguments as first, middle, end iterators
and an optional comparator. Several notes:
- You should not throw exceptions from
Comparefunction. Standard library also does not specify the behavior in that matter. - We don't support ParallelSTL for now.
- C++20 constexpr specifiers might be added but currently we don't have them because of some floating point math in several algorithms.
All functions are in the
miniselectnamespace. See the example for that.pdqselect
- This algorithm is based on
pdqsortwhich is acknowledged as one of the fastest generic sort algorithms. - Location:
miniselect/pdqselect.h. - Functions:
pdqselect,pdqselect_branchless,pdqpartial_sort,pdqpartial_sort_branchless. Branchless version uses branchless partition algorithm provided bypdqsort. Use it if your comparison function is branchless, it might give performance for very big ranges. - Performance advice: Use it when you need to sort a big chunk so that
is close to
.
- This algorithm is based on

- Floyd-Rivest
- This algorithm is based on Floyd-Rivest algorithm.
- Location:
miniselect/floyd_rivest_select.h. - Functions:
floyd_rivest_select,floyd_rivest_partial_sort. - Performance advice: Given that this algorithm performs as one of the best on average case in terms of comparisons and speed, we highly advise to
at least try this in your project. Especially it is good for small
We present here two gifs, for median and for order statistic.


- Median Of Medians
- This algorithm is based on Median of Medians algorithm, one of the first deterministic linear time worst case median algorithm.
- Location:
miniselect/median_of_medians.h. - Functions:
median_of_medians_select,median_of_medians_partial_sort. - Performance advice: This algorithm does not show advantages over others, implemented for historical reasons and for bechmarking.

- Median Of Ninthers
- This algorithm is based on Fast Deterministic Selection paper by Andrei Alexandrescu, one of the latest and fastest deterministic linear time worst case median algorithms.
- Location:
miniselect/median_of_ninthers.h. - Functions:
median_of_ninthers_select,median_of_ninthers_partial_sort. - Performance advice: Use this algorithm if you absolutely need linear time worst case scenario for selection algorithm. This algorithm shows some strengths over other deterministic
PICKalgorithms and has lower constanst than MedianOfMedians.

- Median Of 3 Random
- This algorithm is based on QuickSelect with the random median of 3 pivot choice algorithm (it chooses random 3 elements in the range and takes the middle value). It is a randomized algorithm.
- Location:
miniselect/median_of_3_random.h. - Functions:
median_of_3_random_select,median_of_3_random_partial_sort. - Performance advice: This is a randomized algorithm and also it did not show any strengths against Median Of Ninthers.

- Introselect
- This algorithm is based on Introselect algorithm, it is used in libstdc++ in
std::nth_element, however instead of falling back to MedianOfMedians it is using HeapSelect which adds logarithm to its worst complexity. - Location:
<algorithm>. - Functions:
std::nth_element. - Performance advice: This algorithm is used in standard library and is not recommended to use if you are looking for performance.
- This algorithm is based on Introselect algorithm, it is used in libstdc++ in

- Median Of 3
- This algorithm is based on QuickSelect with median of 3 pivot choice algorithm (the middle value between begin, mid and end values), it is used in libc++ in
std::nth_element. - Location:
<algorithm>. - Functions:
std::nth_element. - Performance advice: This algorithm is used in standard library and is not recommended to use if you are looking for performance.
- This algorithm is based on QuickSelect with median of 3 pivot choice algorithm (the middle value between begin, mid and end values), it is used in libc++ in

std::partial_sortorHeapSelect- This algorithm has heap-based solutions both in libc++ and libstdc++, from the first
- Location:
<algorithm>,miniselect/heap_select.h. - Functions:
std::partial_sort,heap_select,heap_partial_sort. - Performance advice: This algorithm is very good for random data and small
- This algorithm has heap-based solutions both in libc++ and libstdc++, from the first
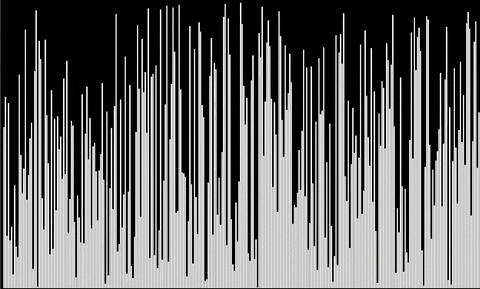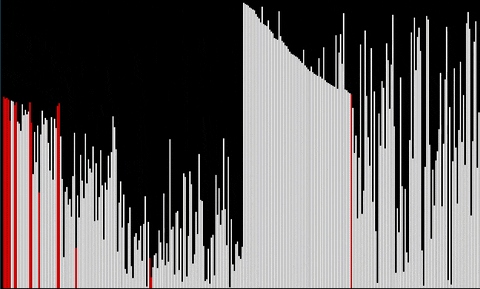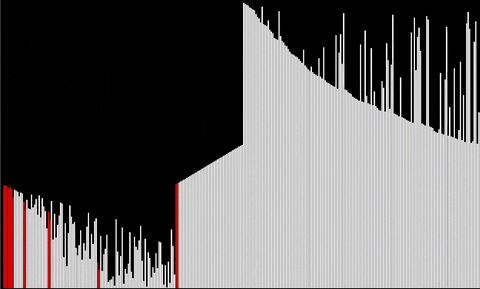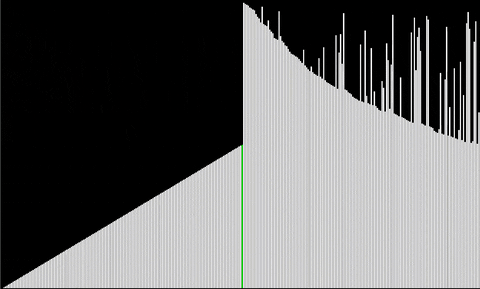
Other algorithms to come
- Kiwiel modification of FloydRivest algorithm which is described in On Floyd and Rivest’s SELECT algorithm with ternary and quintary pivots.
- Combination of FloydRivest and pdqsort pivot strategies, currently all experiments did not show any boost.
Performance results
We use 10 datasets and 8 algorithms with 10000000 elements to find median and
other on
Intel(R) Core(TM) i5-4200H CPU @ 2.80GHz for std::vector<int>,
for median the benchmarks are the following:



For smaller ,
for example, 1000, the results are the following



Other benchmarks can be found here.
Real-world usage
If you are planning to use miniselect in your product, please work from one of our releases and if you wish, you can write the acknowledgment in this section for visibility.
Contributing
Patches are welcome with new algorithms! You should add the selection algorithm together with the partial sorting algorithm in include, add tests in testing and ideally run benchmarks to see how it performs. If you also have some data cases to test against, we would be more than happy to merge them.
Motivation
Firstly the author was interested if any research had been done for small
in selection algorithms and was struggling to find working implementations to
compare different approaches from standard library and quickselect algorithms.
After that it turned out that the problem is much more interesting than it looks
like and after reading The Art of Computer Programming from Donald Knuth about
minimum comparison sorting and selection algorithms the author decided to look
through all non-popular algorithms and try them out.
The author have not found any decent library for selection algorithms and little research is published in open source, so that they decided to merge all that implementations and compare them with possible merging of different ideas into a decent one algorithm for most needs. For a big story of adventures see the author's blog post.
License
The code is made available under the Boost License 1.0.
Third-Party Libraries Used and Adjusted
| Library | License |
|---|---|
| pdqsort | MIT |
| MedianOfNinthers | Boost License 1.0 |