
step-01.md 8.5 KB
Step 1. Netdata's building blocks
Netdata is a distributed and real-time health monitoring and performance troubleshooting toolkit for monitoring your systems and applications.
Because the monitoring agent is highly-optimized, you can install it all your physical systems, containers, IoT devices, and edge devices without disrupting their core function.
By default, and without configuration, Netdata delivers real-time insights into everything happening on the system, from CPU utilization to packet loss on every network device. Netdata can also auto-detect metrics from hundreds of your favorite services and applications, like MySQL/MariaDB, Docker, Nginx, Apache, MongoDB, and more.
All metrics are automatically-updated, providing interactive dashboards that allow you to dive in, discover anomalies, and figure out the root cause analysis of any issue.
Best of all, Netdata is entirely free, open-source software! Solo developers and enterprises with thousands of systems can both use it free of charge. We're hosted on GitHub.
Want to learn about the history of Netdata, and what inspired our CEO to build it in the first place, and where we're headed? Read Costa's comprehensive blog post: Redefining monitoring with Netdata (and how it came to be).
What you'll learn in this step
In the first step of the Netdata guide, you'll learn about:
- Netdata's core features
- Why you should use Netdata
- How Netdata has complementary systems, not competitors
Let's get started!
Netdata's core features
Netdata has only been around for a few years, but it's a complex piece of software. Here are just some of the features we'll cover throughout this guide.
- A sophisticated dashboard, which we'll cover in step 2. The real-time, highly-granular dashboard, with hundreds of charts, is your main source of information about the health and performance of your systems/ applications. We designed the dashboard with anomaly detection and quick analysis in mind. We'll return to dashboard-related topics in both step 7 and step 8.
- Long-term metrics storage by default. With our new database engine, you can store days, weeks, or months of per-second historical metrics. Or you can archive metrics to another database, like MongoDB or Prometheus. We'll cover all these options in step 9.
- No configuration necessary. Without any configuration, you'll get thousands of real-time metrics and hundreds of alarms designed by our community of sysadmin experts. But you can configure Netdata in a lot of ways, some of which we'll cover in step 4.
- Distributed, per-system installation. Instead of centralizing metrics in one location, you install Netdata on every system, and each system is responsible for its metrics. Having distributed agents reduces cost and lets Netdata run on devices with little available resources, such as IoT and edge devices, without affecting their core purpose.
- Sophisticated health monitoring to ensure you always know when an anomaly hits. In step 5, we dive into how you can tune alarms, write your own alarm, and enable two types of notifications.
- High-speed, low-resource collectors that allow you to collect thousands of metrics every second while using only a fraction of your system's CPU resources and a few MiB of RAM.
- Netdata Cloud is our SaaS toolkit that helps Netdata users monitor the health and performance of entire infrastructures, whether they are two or two thousand (or more!) systems. We'll cover Netdata Cloud in step 3.
Why you should use Netdata
Because you care about the health and performance of your systems and applications, and all of the awesome features we just mentioned. And it's free!
All these may be valid reasons, but let's step back and talk about Netdata's principles for health monitoring and performance troubleshooting. We have a lot of complementary systems, and we think there's a good reason why Netdata should always be your first choice when troubleshooting an anomaly.
We built Netdata on four principles.
Per-second data collection
Our first principle is per-second data collection for all metrics.
That matters because you can't monitor a 2-second service-level agreement (SLA) with 10-second metrics. You can't detect quick anomalies if your metrics don't show them.
How do we solve this? By decentralizing monitoring. Each node is responsible for collecting metrics, triggering alarms, and building dashboards locally, and we work hard to ensure it does each step (and others) with remarkable efficiency. For example, Netdata can collect 100,000 metrics every second while using only 9% of a single server-grade CPU core!
By decentralizing monitoring and emphasizing speed at every turn, Netdata helps you scale your health monitoring and performance troubleshooting to an infrastructure of every size. And you get to keep per-second metrics in long-term storage thanks to the database engine.
Unlimited metrics
We believe all metrics are fundamentally important, and all metrics should be available to the user.
If you don't collect all the metrics a system creates, you're only seeing part of the story. It's like saying you've read a book after skipping all but the last ten pages. You only know the ending, not everything that leads to it.
Most monitoring solutions exist to poke you when there's a problem, and then tell you to use a dozen different console tools to find the root cause. Netdata prefers to give you every piece of information you might need to understand why an anomaly happened.
Meaningful presentation
We want every piece of Netdata's dashboard not only to look good and update every second, but also provide context as to what you're looking at and why it matters.
The principle of meaningful presentation is fundamental to our dashboard's user experience (UX). We could have put charts in a grid or hidden some behind tabs or buttons. We instead chose to stack them vertically, on a single page, so you can visually see how, for example, a jump in disk usage can also increase system load.
Here's an example of a system undergoing a disk stress test:
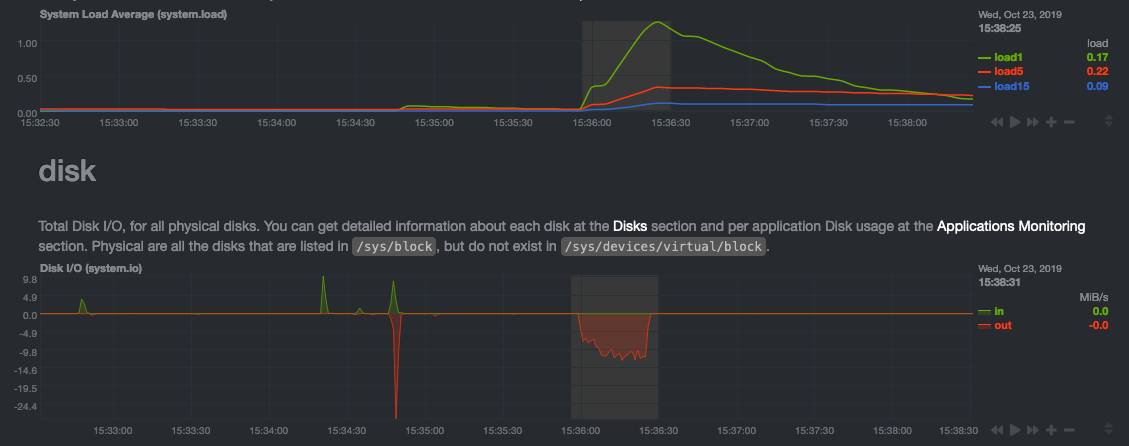
For the curious, here's the command:
stress-ng --fallocate 4 --fallocate-bytes 4g --timeout 1m --metrics --verify --times!
Immediate results
Finally, Netdata should be usable from the moment you install it.
As we've talked about, and as you'll learn in the following nine steps, Netdata comes installed with:
- Auto-detected metrics
- Human-readable units
- Metrics that are structured into charts, families, and contexts
- Automatically generated dashboards
- Charts designed for visual anomaly detection
- Hundreds of pre-configured alarms
By standardizing your monitoring infrastructure, Netdata tries to make at least one part of your administrative tasks easy!
How Netdata has complementary systems, not competitors
We'll cover this quickly, as you're probably eager to get on with using Netdata itself.
We don't want to lock you in to using Netdata by itself, and forever. By supporting archiving to external databases like Graphite, Prometheus, OpenTSDB, MongoDB, and others, you can use Netdata in conjunction with software that might seem like our competitors.
We don't want to "wage war" with another monitoring solution, whether it's commercial, open-source, or anything in between. We just want to give you all the metrics every second, and what you do with them next is your business, not ours. Our mission is helping people create more extraordinary infrastructures!
What's next?
We think it's imperative you understand why we built Netdata the way we did. But now that we have that behind us, let's get right into that dashboard you've heard so much about.