metric-correlations.md 8.5 KB
Metric Correlations
The Metric Correlations feature lets you quickly find metrics and charts related to a particular window of interest that you want to explore further.
By displaying the standard Netdata dashboard, filtered to show only charts that are relevant to the window of interest, you can get to the root cause sooner.
Because Metric Correlations uses every available metric from your infrastructure, with as high as 1-second granularity, you get the most accurate insights using every possible metric.
Using Metric Correlations
When viewing the Metrics tab or a single-node dashboard, the Metric Correlations button appears in the top right corner of the page.
To start correlating metrics, click the Metric Correlations button, highlight a selection of metrics on a single chart. The selected timeframe needs at least 15 seconds for Metric Correlation to work.
The menu then displays information about the selected area and reference baseline. Metric Correlations uses the reference baseline to discover which additional metrics are most closely connected to the selected metrics. The reference baseline is based upon the period immediately preceding the highlighted window and is the length of 4 times the highlighted window. This is to ensure that the reference baseline is always immediately before the highlighted window of interest and a bit longer so as to ensure it's a more representative short term baseline.
Click the Find Correlations button to begin the correlation process. This button is only active if a valid timeframe is selected. Once clicked, the process will evaluate all available metrics on your nodes and return a filtered version of the Netdata dashboard. You will now only see the metrics that changed the most between the base window and the highlighted window you selected..
These charts are fully interactive, and whenever possible, will only show the dimensions related to the timeline you selected.
If you find something else interesting in the results, you can select another window and press Find Correlations again to kick the process off again.
Metric Correlations options
MC enables a few input parameters that users can define to iteratively explore their data in different ways. As is usually the case in Machine Learning (ML), there is no "one size fits all" algorithm, what approach works best will typically depend on the type of data (which can be very different from one metric to the next) and even the nature of the event or incident you might be exploring in Netdata.
So when you first run MC it will use the most sensible and general defaults. But you can also then vary any of the below options to explore further.
Method
There are two algorithms available that aim to score metrics based on how much they have changed between the baseline and highlight windows.
KS2- A statistical test (Two-sample Kolmogorov Smirnov) comparing the distribution of the highlighted window to the baseline to try and quantify which metrics have most evidence of a significant change. You can explore our implementation here.Volume- A heuristic measure based on the percentage change in averages between highlighted window and baseline, with various edge cases sensibly controlled for. You can explore our implementation here.
Aggregation
Behind the scenes, Netdata will aggregate the raw data as needed such that arbitrary window lengths can be selected for MC. By default, Netdata will just Average raw data when needed as part of pre-processing. However other aggregations like Median, Min, Max, Stddev are also possible.
Data
Unlike other observability agents that only collect raw metrics, Netdata also assigns an Anomaly Bit in real-time. This bit flags whether a metric is within normal ranges (0) or deviates significantly (1). This built-in anomaly detection allows for the analysis of both the raw data and the anomaly rates.
Note: Read more here to learn more about the native anomaly detection features within netdata.
Metrics- Run MC on the raw metric values.Anomaly Rate- Run MC on the corresponding anomaly rate for each metric.
Metric Correlations on the Agent
When a Metric Correlations request is made to Netdata Cloud, if any node instances have MC enabled then the request will be routed to the node instance with the highest hops (e.g. a parent node if one is found or the node itself if not). If no node instances have MC enabled then the request will be routed to the original Netdata Cloud based service which will request input data from the nodes and run the computation within the Netdata Cloud backend.
Usage tips
- When running Metric Correlations from the Metrics tab across multiple nodes, you might find better results if you iterate on the initial results by grouping by node to then filter to nodes of interest and rerun the Metric Correlations. So a typical workflow in this case would be to:
- If unsure which nodes you are interested in then run MC on all nodes.
- Within the initial results returned group the most interesting chart by node to see if the changes are across all nodes or a subset of nodes.
- If you see a subset of nodes clearly jump out when you group by node, then filter for just those nodes of interest and run the MC again. This will result in less aggregation needing to be done by Netdata and so should help give clearer results as you interact with the slider.
- Use the
Volumealgorithm for metrics with a lot of gaps (e.g. request latency when there are few requests), otherwise stick withKS2- By default, Netdata uses the
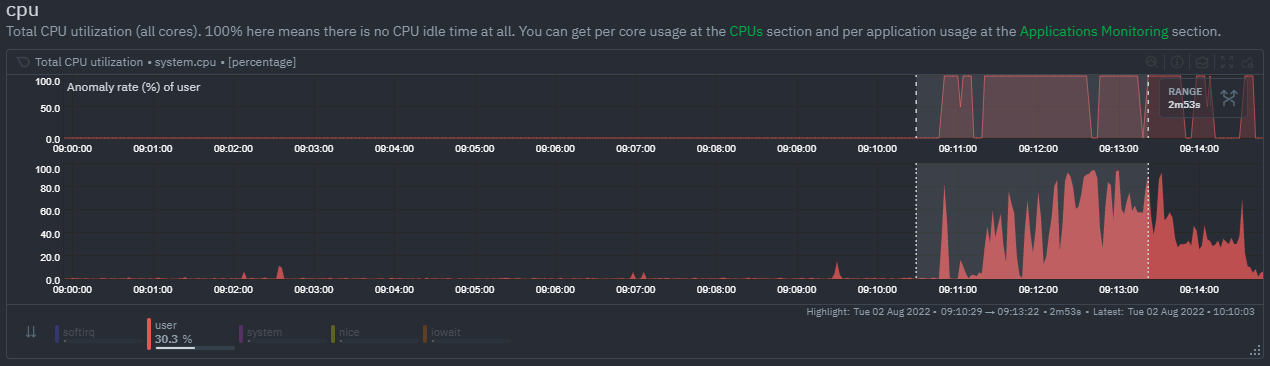
KS2algorithm which is a tried and tested method for change detection in a lot of domains. The Wikipedia article gives a good overview of how this works. Basically, it is comparing, for each metric, its cumulative distribution in the highlight window with its cumulative distribution in the baseline window. The statistical test then seeks to quantify the extent to which we can say these two distributions look similar enough to be considered the same or not. TheVolumealgorithm is a bit more simple thanKS2in that it basically compares (with some edge cases sensibly handled) the average value of the metric across baseline and highlight and looks at the percentage change. Often bothKS2andVolumewill have significant agreement and return similar metrics. Volumemight favour picking up more sparse metrics that were relatively flat and then came to life with some spikes (or vice versa). This is because for such metrics that just don't have that many different values in them, it is impossible to construct a cumulative distribution that can then be compared. SoVolumemight be useful in spotting examples of metrics turning on or off.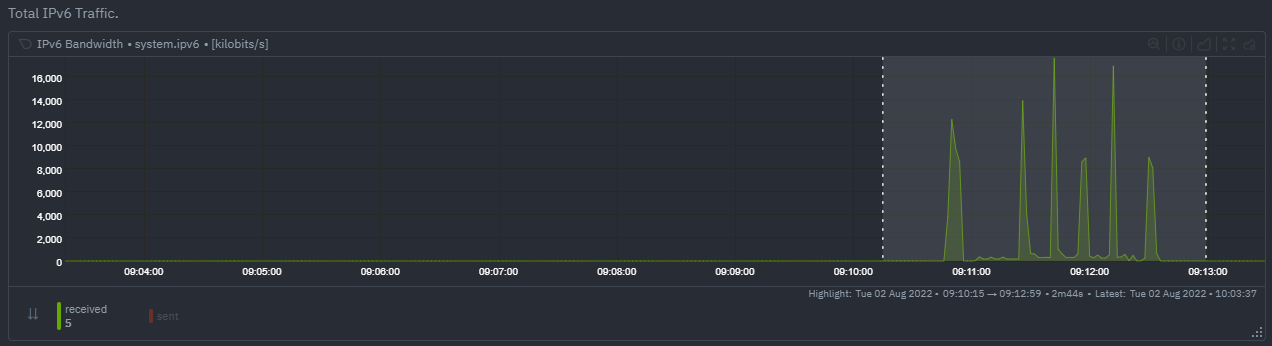
KS2since it relies on the full distribution might be better at highlighting more complex changes thatVolumeis unable to capture. For example a change in the variation of a metric might be picked up easily byKS2but missed (or just much lower scored) byVolumesince the averages might remain not all that different between baseline and highlight even if their variance has changed a lot.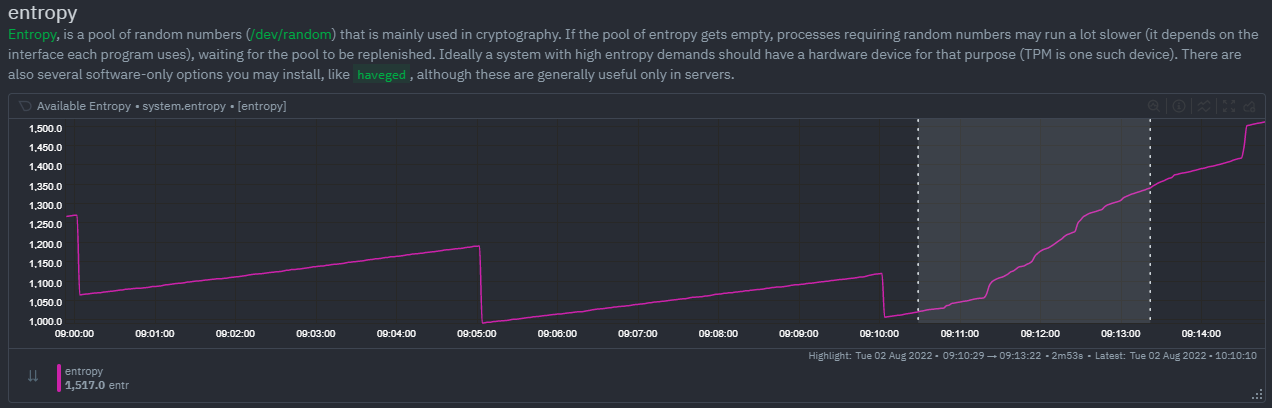
- By default, Netdata uses the
- Use
VolumeandAnomaly Ratetogether to ask what metrics have turned most anomalous from baseline to highlighted window. You can expand the embedded anomaly rate chart once you have results to see this more clearly.